Currently we are suffering from COVID-19, and the situation is very serious. Some people say that the virus of COVID-19 is very similar with SARS, however based on the point of view of data science, they are different.
The purpose of this project is to help doctors to diagnose COVID-19 and the goal of this project is based on chest x-ray images to predict if a patient is normal, attacked by Covid-19 or by other virus/bacterias.

Dataset
The data is from Kaggle and it contains metadata, train folder and test folder which contain chest x-ray images. There are two main problems of this dataset. First, there is no any Covid-19 images in test folder. The second problem is some names of images which are in train folder are not in ‘X_ray_image_name’ in metadata.csv, so we need to remove those images whose names are not in metadata.csv.

Import packages
from keras.layers import Dense,Dropout,Activation
from sklearn.metrics import f1_score
import numpy as np
import pandas as pd
import os
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import seaborn as sns
sns.set()
import tensorflow as tf
from tensorflow.python import keras
from keras.models import Model, Sequential
import cv2
from keras import regularizersData Cleansing and Data Preprocessing
First thing we need to do is to re-label some COVID-19 images’ names from “TRAIN” to “TEST” in metadata
# I moved round 20% of 58 which are 11 COVID-19 images from train folder to test folder
test_covid_name=list(meta_filled[meta_filled.Label_2_Virus_category=='COVID-19'].X_ray_image_name[-11:])# if any name of X_ray_image_name in test_covid_name
#the corresponding Dataset_type will change into "TEST'
for i in range(len(metadata)):
if metadata['X_ray_image_name'].iloc[i] in test_covid_name:
metadata['Dataset_type'].iloc[i]='TEST'
else:
metadata['Dataset_type'].iloc[i]
After changed the labels, we need to move those images to test folder
import shutilfor img in test_covid_name:
# Source path
covid_test_img= '/Coronahack-Chest-XRay-Dataset/train/{}'.format(img) # Destination path
test_folder = '/Coronahack-Chest-XRay-Dataset/test' # Move the content of
# source to destination
dest = shutil.move(covid_test_img, test_folder)
The target in this dataset is very ambiguous, because there are three different labels and the “Label” column only contains two values either normal or pneumonia which cannot give us more information about COVID-19. Now let us change the “Label” column a little bit — if the row in ‘Label_2_Virus_category’ shows COVID-19 then the same row of ‘Label’ change into COVID-19.
# Then Change the Label if Label_2_Virus_category== COVID-19 , Label= COVID-19
for i in range(len(metadata)):
if metadata['Label_2_Virus_category'][i]=='COVID-19':
metadata['Label'][i]='COVID-19'# make sure our target is ternary
metadata.groupby('Dataset_type')['Label'].value_counts()output:
Dataset_type Label
TEST Pnemonia 390
Normal 234
COVID-19 11
TRAIN Pnemonia 3886
Normal 1342
COVID-19 47# Then declare train label and test label
train_label= meta_filled[meta_filled['Dataset_type'] == 'TRAIN']
test_label= meta_filled[meta_filled['Dataset_type'] == 'TEST']
Now, it’s time to remove some images whose name are not in ‘X_ray_image_name’ column.
# First, obtain the all images name from train and test folders
import os
TRAIN_IMGS = os.listdir(TRAIN_FOLDER)
TEST_IMGS = os.listdir(TEST_FOLDER)# Second, to check how many images' names are not in the column
missing_img=[]
for img in TRAIN_IMGS:
if img not in list(train_label['X_ray_image_name']):
missing_img.append(img)# Third, remove missing images from the train folder if the images name is not in the metadata
def remove_img(path, img_name):
os.remove(path + '/' + img_name)
# check if file exists or not
if os.path.exists(path + '/' + img_name) is False:
# file did not exists
return True#remove images using the function
for name in missing_img:
remove_img(TRAIN_FOLDER, name)# Finally, match the image names and the images so that we can get correct order with our target
train=pd.DataFrame()
train['X_ray_image_name']=TRAIN_IMGStest=pd.DataFrame()
test['X_ray_image_name']=TEST_IMGS# merge dataframes
con_train=pd.merge(train,train_label,on='X_ray_image_name')
con_test=pd.merge(test,test_label,on='X_ray_image_name')# make sure the images orders are same
list(con_train.X_ray_image_name)==list(train.X_ray_image_name)# Declare y_train and y_test
y_train=con_train.Label.map({'COVID-19':0, 'Normal':1, 'Pnemonia':2})
y_test =con_test.Label.map({'COVID-19':0, 'Normal':1, 'Pnemonia':2})
We’ve finished most important part, now let’s take a look an image from train folder. The shape of this image are (736, 1048) which is slightly large. Besides, other images have different shapes and colors so what we need to do is resize and re-color all the images.
# A function to obtain image data from corresponding folder then
# convert them into array type, then recolor and resize them.
def create_data(path):
list_new_array=[]
for img in os.listdir(path):
try:
img_array=cv2.imread(os.path.join(path,img)
,cv2.IMREAD_GRAYSCALE)
size=100
new_array=cv2.resize(img_array,(size,size))
list_new_array.append(new_array)
except Exception as e:
pass
return list_new_array#generate test_data
test_data=create_data(TEST_FOLDER)
train_data=create_data(TRAIN_FOLDER)#reshape the data
x_train = np.array(train_data).reshape(5275, 100*100).astype('float32')
x_test = np.array(test_data).reshape(635, 100*100).astype('float32')# Check the shape
np.array(train_data).shape , np.array(test_data).shape
output:
((5275, 10000), (635, 10000))
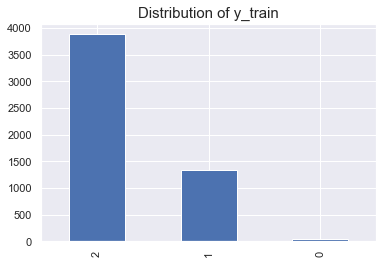
In the train dataset, we have three different classes which are normal, COVID-19 and other pneumonia, however they are not balanced. If we want to have better accuracy for our prediction, we want to resample our data and here I applied oversampling method. ( the code of oversampling method)
The last part of data cleansing and preprocessing is normalize data and encode our labels.
# Normalize the data
X_train = x_train/255.
X_test = x_test/255.#Use the function to_categorical() to one-hot encode our labels.
Y_train = tf.keras.utils.to_categorical(y_train, 3)
Y_test = tf.keras.utils.to_categorical(y_test, 3)
EDA
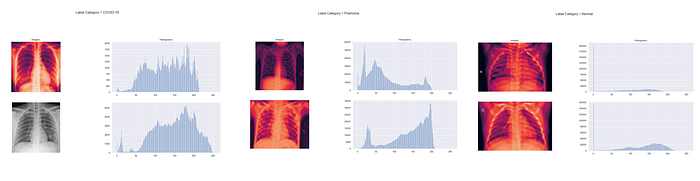
The first column of this histogram is ‘COVID-19' x-ray images, the second column is pneumonia images and the last column shows the normal patients’ chest x-ray images. Obviously, the normal ones are very smooth, on the other hand the distributions of histograms of COVID_19 are more centrical than other types of pneumonia. Distributions of other types of pneumonia are more skewed. As I mentioned before, based on the point of view of data science they are different.
Neural NetWork
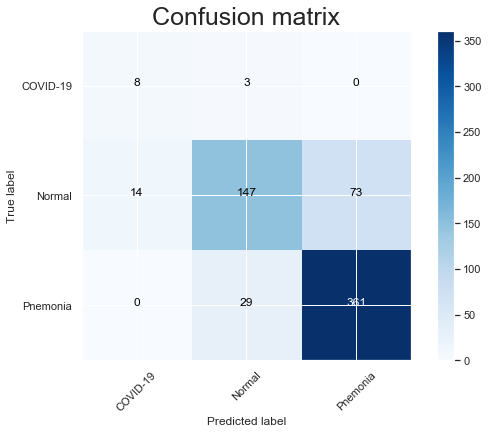
Modeling part is the most exciting part. After tuning the hyper-parameters( the process of tuning the hyper-parameters link), we can get our maximum score and better results. Based on the confusion matrix, the model can 100% distinguish COVID-19 pneumonia and other types of pneumonia. (again based on the point of view of data science they are different).
model_1 = Sequential()
model_1.add(Dense(32, activation='softsign',kernel_initializer='glorot_normal',kernel_regularizer=regularizers.l2(0.005),input_shape=(10000,)))model_1.add(Dense(60,kernel_regularizer=regularizers.l2(0.005),activation='sigmoid'))
model_1.add(Dropout(0.3))model_1.add(Dense(60,kernel_regularizer=regularizers.l2(0.005),activation='tanh'))
model_1.add(Dropout(0.3))model_1.add(Dense(3, activation='softmax'))opt = SGD(lr=0.01, momentum=0.8)
model_1.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])results_1 = model_1.fit(X_train, Y_train, epochs=50, batch_size=50 ,validation_data=(X_test, Y_test))
Results:
- Training Accuracy: 0.9781
- Testing Accuracy: 0.8173
- Train data f1_Score:0.98
- Test data f1_Score:0.81
Conclusion:
I also applied Random Forest for this dataset if you are interested you can visit my github, but Neural Network (NN) performed better than Random Forest. There are only 11 COVID-19 images in test folder, and I believe that if there are more COVID-19 images and more experimenting, the result can be improved.
