
What is an API?
API is the acronym for Application Programming Interface, which is a software intermediary that allows two applications to talk to each other. The GitHub API is provided by GitHub for developers who want to develop applications targeting GitHub.
Get your token
If you want to extract more data without limitation, you need to create a token from GitHub. Proceed as follows:
- Step 1: Login GitHub with your user name and password
- Step 2: Click your icon on the right top and click “settings”

- Step 3: Scroll down and click “Developer settings”

- Step 4: Click “personal access token” on a new page then click “Generate New Token”

- Step 5: It will require your GitHub password
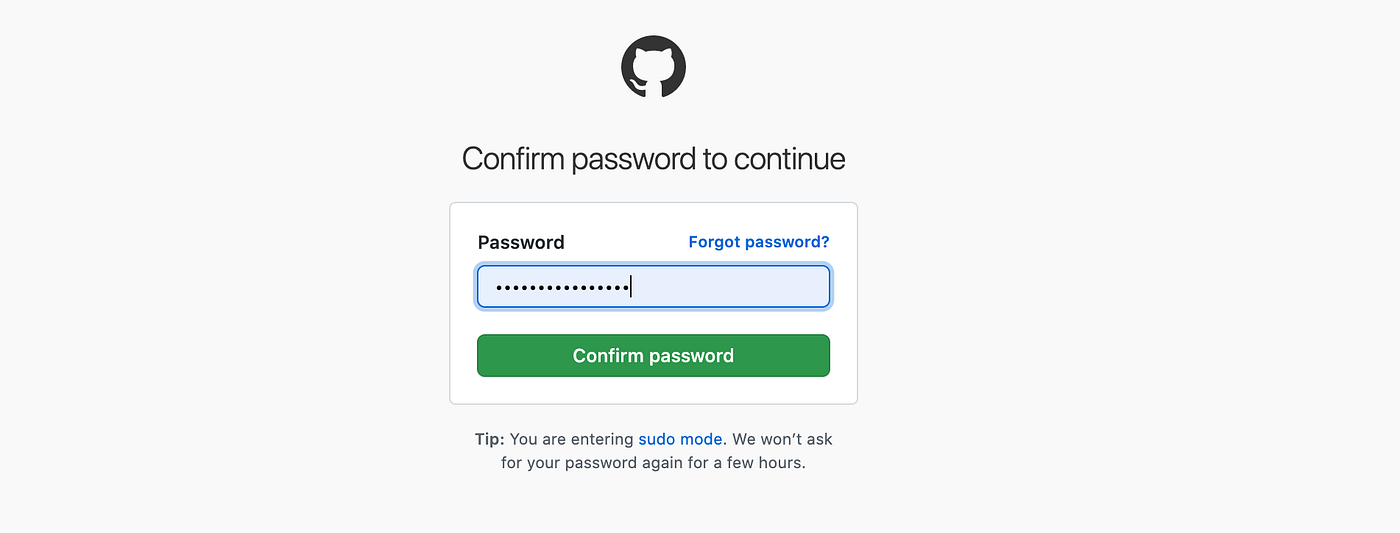
- Step 6: After you enter your password you can see a new page, and on the top, you can see “Note”. Here you can name your token and select the appropriate scopes.

- Step 7: Scroll down to the bottom and click “Generate Token”, then you can get you token on a new page.

Code in Python
In this section, I choose the Amazon Web Services Labs- awslabs which has open-source repositories(repos). Let us try to obtain all contributors based on the sum of their contributions across all repositories.
Step 1: You need to copy & paste your token and create your headers.
# setup owner name , access_token, and headers
owner='awslabs'
access_token='your_token_from_GitHub'
headers = {'Authorization':"Token "+access_token}Step 2: Extract All Repos’ Names
This URL — “https://api.github.com/users/{owner}/repos?page={page_num}” can help us to get all the repos’ name and their information from one page. So what we need to do is to loop through each page and extract all the open-source repos from the first page to the last page. Of course, the data we will get is JSON data.
# loop through all pages to obtain all the repos' informationrepos=[]
for page_num in range(1,300):
try:
# to find all the repos' names from each page
url=f"https://api.github.com/users/{owner}/repos?page={page_num}"
repo=requests.get(url,headers=headers).json()
repos.append(repo)
except:
repos.append(None)
Then let us see how many pages under awslabs.
for page in repos:
if page==[]:
print(repos.index(page))
break
# there are 17 pages
>>> 17
# each page has 30 repos
len(repos[1])
>>> 30Step 3: The image below shows the “repos” structure and we need to extract “full_name” from each repo’s information.
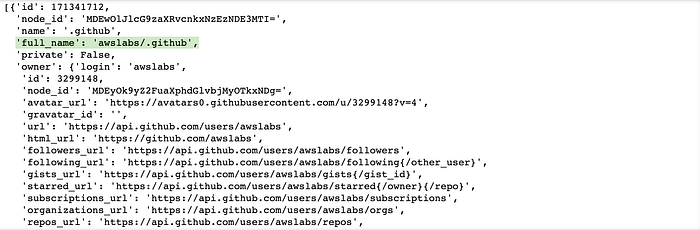
# after we obtianed all the repos information under the awslabs, next let us get the repos full_name all_repo_names=[]
for page in repos:
for repo in page:
try:
all_repo_names.append(repo['full_name'].split("/")[1])
except:
passlen(all_repo_names)
>>> 494 # there are 494 repos
Step 4: Now we need to loop through each repo to obtain all the contributors' information, but one thing that I want to mention is one person can commit to different repos, so the names in all_contributors are not unique.
# collect all contributors from each repoall_contributors=[] # create an empty coontainer
for repo_name in all_repo_names:
url = f"https://api.github.com/repos/{owner}/{repo_name}/contributors"# make the request and return the json
contributors= requests.get(url,headers=headers).json()
all_contributors.append(contributors)
Let us take a look at the first contributor’s information.
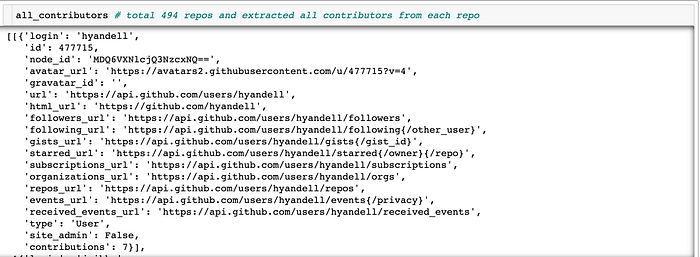
Step 5: The “login” is the contributor’s name and the very last one “ contributions” is the number shows how many times that the person commits to a repo. Let us extract those two pieces of data from “all_contributors”.
# collect contributors names and their contribution count
names=[]
counts=[]
for repo in all_contributors:
for contributor in repo:
try:
name=contributor['login']
count=contributor['contributions']
names.append(name)
counts.append(count)
except:
Nonelen(names) # there are total 3501
>>> 3501
Step 6: We need to store their names and contribution counts into a data frame named “mydata”. Then we can use “groupby” and ‘sum()’ to get unique contributors’ names and sum up contribution counts. Finally “.head(n)” can be applied to observe top n contributors.
# create a dataframe and store the contrbutors' names and their contribution counts
mydata=pd.DataFrame()
mydata['contributor_name']=names
mydata['counts']=counts# Then obtain unique names with sum of their contribution counts
mydata=mydata.groupby('contributor_name')["counts"].sum().reset_index().sort_values(by='counts',ascending=False)# drop None / missing values
mydata=mydata.dropna(axis=0).reset_index().drop(columns='index')# get top 10 contributiors
mydata.head(10) # top 10 contributors

For more information and code details please visit my GitHub.
